SculptDiff: Diffusion Policy for Robotic Sculpting
Mechanical and AI Lab
Carnegie Mellon University
Pittsburgh, PA
October 2023 - March 2024
Accepted to IROS 2024
The manipulation of deformable objects continues to present challenges within robotics due to the complexities of state estimation, long-horizon planning, and predicting the deformations resulting from interactions. These challenges are particularly pronounced with 3D deformable objects. SculptDiff is proposed as a goal-conditioned imitation learning framework, utilizing point cloud state observations to directly learn clay sculpting policies for various target shapes. This project represents the first real-world method that has successfully learned manipulation policies for 3D deformable objects.
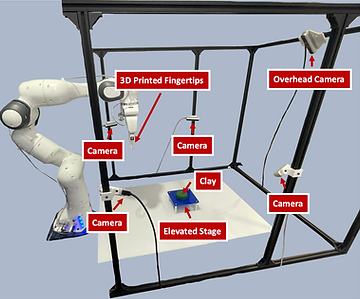
The experimental setup includes 4 RGB-D cameras mounted to a camera cage to reconstruct the clay point cloud. We fit the robot with 3D printed fingertips and an elevated stage. We assume the clay always remains centered and fixed to the elevated stage
Sculpting clay into target shapes requires accurate 3D geometry representation, achieved through point clouds rather than RGB or RGB-D observations. Point clouds improve robot performance and resilience to environmental changes and enable dataset augmentation, reducing the need for extensive hardware demonstrations. Four Intel RealSense D415 cameras capture the 3D point cloud of the clay, which is then processed to isolate and downsample the clay data. This comprehensive state representation is crucial for training effective sculpting policies.

The intermediate 3D point cloud states as the clay is sculpted with the SculptDiff policy compared to the target shape point cloud. The lightness of each point is correlated with the point's z-value to visualize depth.
A diffusion policy combined with point cloud state and goal inputs is used for the robotics sculpting task. The robot policy is represented as a denoising diffusion probabilistic model (DDPM), which iteratively denoises an input sampled from Gaussian noise, approximating the conditional distribution of actions given observations. A 1D CNN-based diffusion policy is employed, using a PointBERT encoder to generate latent embeddings of the clay state and goal point clouds. These embeddings are further refined through a two-layer MLP projection head. The resulting observation vector, comprising the clay state, goal, and previous sculpting action, conditions the diffusion process, enabling effective learning of sculpting sequences. This approach leverages the benefits of point clouds for accurate 3D representation and dataset augmentation, improving the efficiency and performance of the sculpting policy.

The pipeline of SculptDiff. The state and goal point clouds are encoded with PointBERT and a linear projection head to create a latent conditioning observation along with the previous action executed by the robot. The latent state and goal observations as well as the previous action are the conditioning information used to condition the denoising diffusion process for diffusion policy to generate the predicted action sequence.
The human demonstration dataset for SculptDiff was collected through kinesthetic teaching, where an expert physically moved the robot to sculpt the clay into shapes like 'X', 'Line', and 'Cone'. 10 demonstration trajectories for each shape were recorded, capturing the point cloud state of the clay before and after each grasp. To evaluate SculptDiff, it was compared to two state-of-the-art imitation learning frameworks: ACT and VINN. Both ACT and VINN, originally designed for image inputs, were adapted to use the same point cloud embedding and goal conditioning strategy proposed for SculptDiff. The experiments demonstrated that SculptDiff's success is due to its access to 3D information via point cloud observations and goals, as well as the stochastic nature of the diffusion policy.

The TSNE embeddings for PointBERT with different training strategies on the X shape demonstration dataset. The colorbar of state index indicates the state number ranging from 0 to 7 for the states in each demonstration trajectory for the X shape

X

Cone

Line
Read the full report below: